arXiv Audio & Speech 论文日报
EESS.AS 类别 · 2026-04-04 · 共 3 篇
We introduce GAP-URGENet, a generative-predictive fusion framework developed for Track 1 of the ICASSP 2026 URGENT Challenge. The system integrates a generative branch, which performs full-stack speech restoration in a self-supervised representation domain and reconstructs the waveform via a neural vocoder, along with a predictive branch that performs spectrogram-domain enhancement, providing complementary cues. Outputs from both branches are fused by a post-processing module, which also performs bandwidth extension to generate the enhanced waveform at 48 kHz, later downsampled to the original sampling rate. This generative-predictive fusion improves robustness and perceptual quality, achieving top performance in the blind-test phase and ranking 1st in the objective evaluation. Audio examples are available at https://xiaobin-rong.github.io/gap-urgenet_demo.

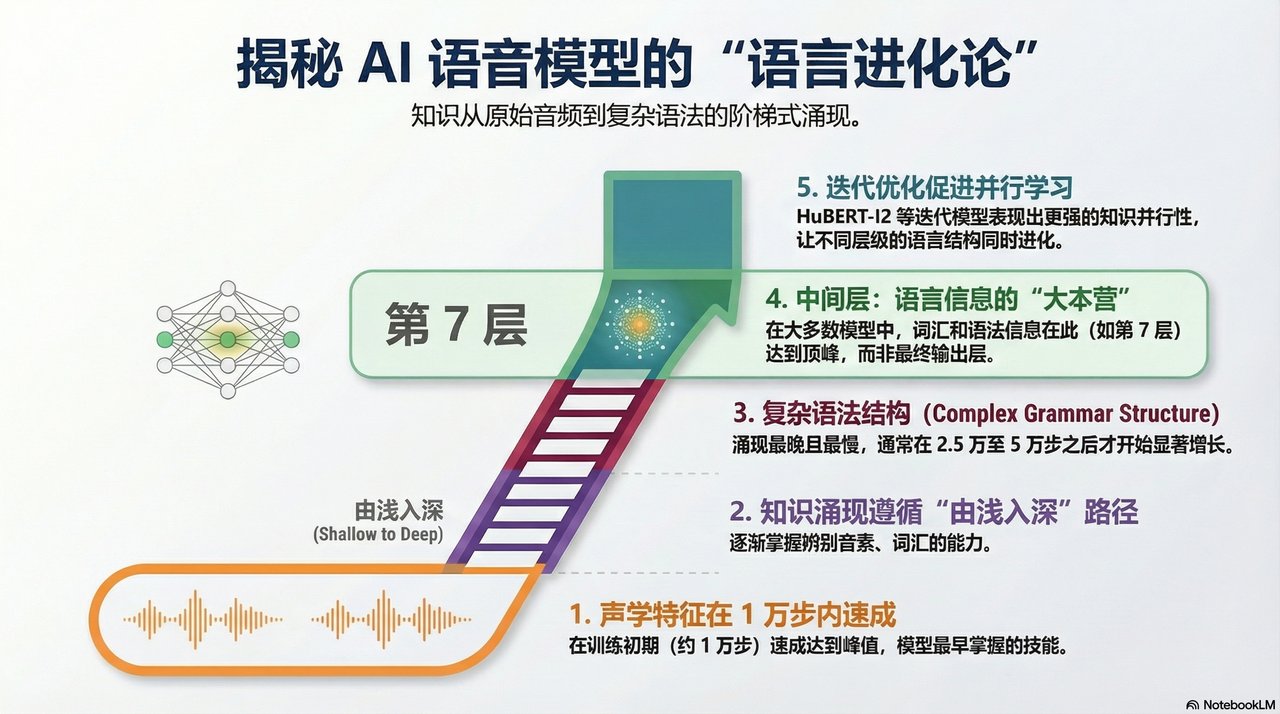
Self-supervised speech models learn effective representations of spoken language, which have been shown to reflect various aspects of linguistic structure. But when does such structure emerge in model training? We study the encoding of a wide range of linguistic structures, across layers and intermediate checkpoints of six Wav2Vec2 and HuBERT models trained on spoken Dutch. We find that different levels of linguistic structure show notably distinct layerwise patterns as well as learning trajectories, which can partially be explained by differences in their degree of abstraction from the acoustic signal and the timescale at which information from the input is integrated. Moreover, we find that the level at which pre-training objectives are defined strongly affects both the layerwise organization and the learning trajectories of linguistic structures, with greater parallelism induced by higher-order prediction tasks (i.e. iteratively refined pseudo-labels).
3
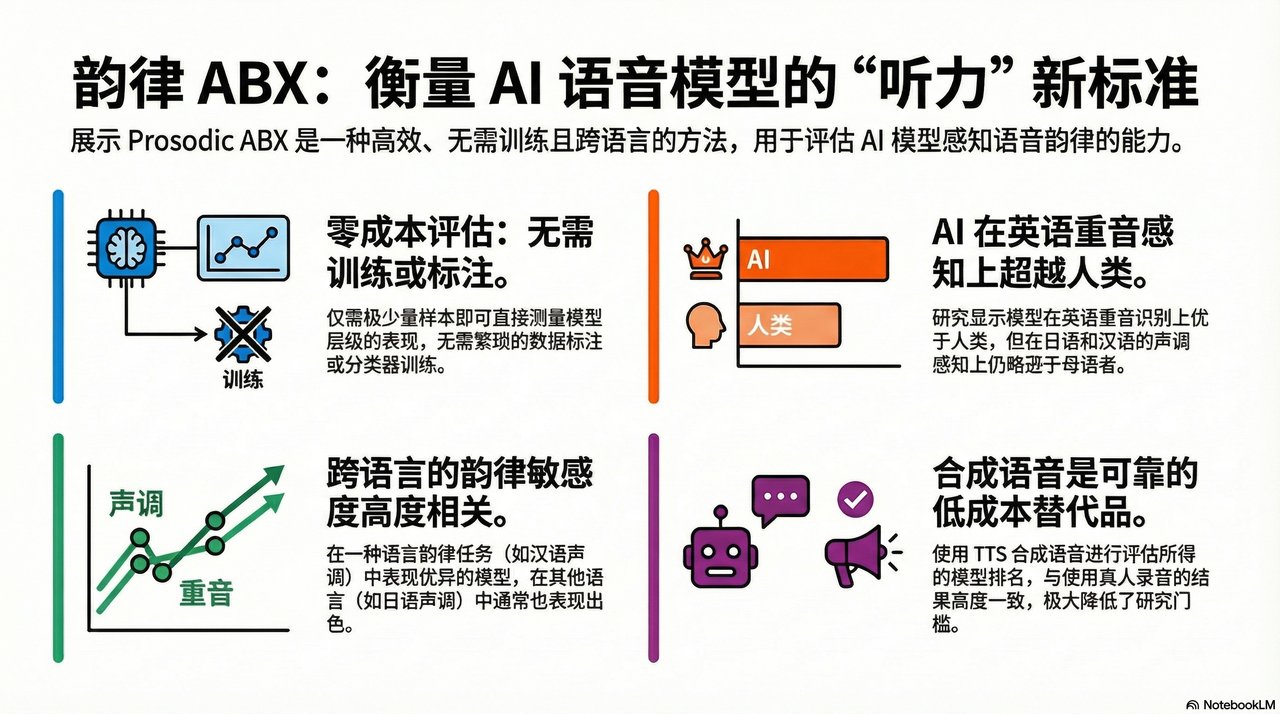
Prosodic ABX: A Language-Agnostic Method for Measuring Prosodic Contrast in Speech Representations
Speech representations from self-supervised speech models (S3Ms) are known to be sensitive to phonemic contrasts, but their sensitivity to prosodic contrasts has not been directly measured. The ABX discrimination task has been used to measure phonemic contrast in S3M representations via minimal pairs. We introduce prosodic ABX, an extension of this framework to evaluate prosodic contrast with only a handful of examples and no explicit labels. Also, we build and release a dataset of English and Japanese minimal pairs and use it along with a Mandarin dataset to evaluate contrast in English stress, Japanese pitch accent, and Mandarin tone. Finally, we show that model and layer rankings are often preserved across several experimental conditions, making it practical for low-resource settings.